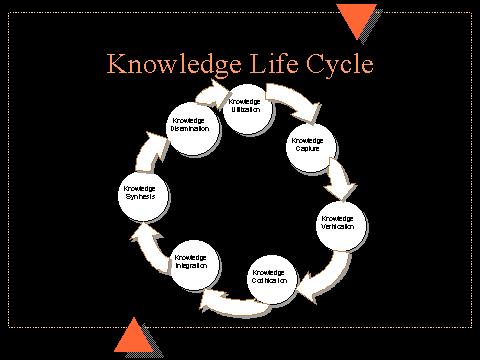
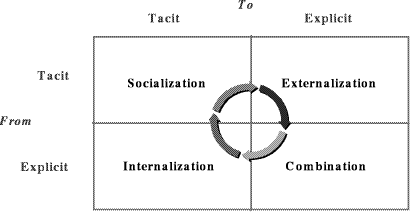
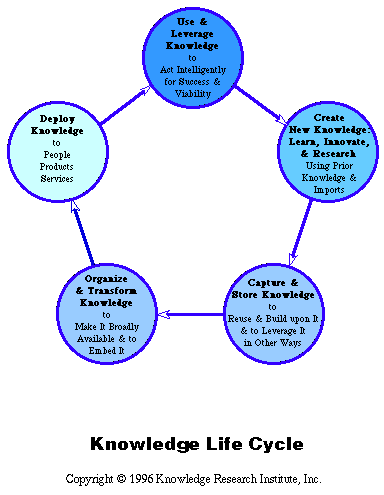
Responses to knowledge queries are more efficient because patterns have
already been pre-computed. Delays are
avoided and follow-up questions are answered quickly, because no analysis
is needed.
The overall computational burden is reduced by avoiding the repeated discovery
sessions that are unknowingly
performed by multiple analysts. In many cases, avoiding the repeated discovery
sessions performed by the same
analyst is itself a significant benefit.
With the
knowledge access paradigm the user still performs analysis (e.g. visualizes
affinity patterns) but the results
delivered
for the same level of computational effort are orders of magnitude better
because the user now analyzes refined
knowledge,
not data. The knowledge access paradigm increases information quality in
two distinct ways:
The central knowledge repository increases the consistency and quality
of knowledge. Random decisions that users
inevitably make when dealing with complex business data are by-passed.
This avoids the fragmented analyses that
significantly reduce corporate knowledge quality as different users draw
different conclusions from the same data.
Because the Data Mining SuiteTM automatically analyzes the entire data
set and not a sample, the likelihood of
errors decreases. And because the system accesses native data directly
in SQL repositories data types (such as
numeric and non-numerics) are naturally managed without coding, producing
higher quality results.
As our
reliance on our computers increases each day, the need for quality can
not be over emphasized. Click here for the
paper
Quality Unbound. Or please click here to see how the Rapid Pilot Knowledge
Access Program can help you
get started
quickly and easily to deliver knowledge to business users in a cost effective
manner.
Defining Information Quality
"Beauty is in the eye of the beholder."
Margaret Hungerford in Molly Baun
Before one can measure and improve information quality, one must be
able to define it in ways that are both meaningful and
measurable.
Information quality is defined in this chapterwhat it is and what it
is not. In order to understand information quality, data
and information and their key concepts must be defined. Knowledge and
wisdom are also defined, because this is where
information impacts business performance, and where nonquality information
can harm that performance.
In defining information quality, we differentiate between inherent and
pragmatic information quality. Essentially, inherent
quality is the correctness of facts; pragmatic quality is the correctness
of the right facts presented correctly. Chapter 2
concludes with defining the three components required for information
quality: data definition and information architecture
quality, data content quality, and data presentation quality.
What Is Quality?
The best way to look at information quality is to look at what quality
means in the general marketplace and then translate what quality
means for information. As consumers, human beings consciously or subconsciously
judge the "quality" of things in their experience. A
conscious application of quality measurement is when a person compares
products in a store and chooses one of them as the "right"
product. "Right" here means selecting the product that best meets ones
overall needs, not necessarily the best features in every category.
After purchase, as a person uses the product, he or she will determine
its quality based on whether that product for its price met the
expectations for its intended use.
An unconscious application of quality measurement is the frustration
one gets with a nonquality product or a service. Waiting in a long line
at a store checkout while store clerks who are capable of coming to
a checkout stand idly by, is an experience in nonquality service. It
communicates that the store is not concerned about their customers
time.
Quality Is Not . . .
First, let us define what quality is not. Quality is not luxury or superiority,
nor is it "best" in class. Quality exists solely in the eyes of the
customers based on the value they perceive on how something meets their
needs. What is quality to one customer may be totally
defective to another.
Take, for example, the diagnosis code of "broken leg" in 80 percent
of the claims mentioned earlier. That was acceptable quality to the
claims processors, because the only requirement to pay a claim was
that it had a valid diagnosis code. But to the actuary, as a data
warehouse customer and the ultimate "customer" of that data, it was
nonquality and completely unusable for risk analysis. The second or
so saved in the claim processors time was more than offset by the
inability of the actuary to analyze the companys risk or understand its
own customers needs.
A far worse scenario exists. What if the medical diagnosis codes were
indiscriminately applied to the claims? What if those incorrect
codes resulted in no unusual pattern that called attention to itself
that something might be askew? Then, what if the actuary determined
risks based on that inaccurate data? What if insurance policies were
then priced based on those (questionable) risks? What if the
customer service group sent out form letters to find out how well their
customers were recovering from their "[medical diagnosis]"? What
if. . . .
Quality is not fitness for purpose. The diagnosis code of "broken leg"
"was fit for purpose" to pay a claim. But it was not fit to analyze
risk. Quality is fitness for all purposes made of the data, including
the likely future uses. Quality information will be used in many new
ways in the intelligent learning organization. Information fit for
one purpose but lacking inherent quality will stunt the intellectual growth
of
the learning organization.
Quality is not subjective or intangible. It can be measured with the
most fundamental business measuresimpact on the bottom line. The
business measures of information quality are described in Chapter 7,
"Measuring Nonquality Information Costs."
Quality Is . . .
What, then, is quality? Total Quality Management provides a useful definition of quality: "consistently meeting customers expectations."1
1 Larry English, Information Quality Improvement: Principles, Methods,
and Management. Seminar 5th Ed (Brentwood, TN: INFORMATION IMPACT
International, Inc., 1996) p. 1.2.
When quality expert Philip Crosby defines quality as "conformance to
requirements,"2 he does not imply simply conformation to written
specifications.
2 Philip Crosby, Quality Is Free (Penguin Group, 1979), p. 15.
Customers requirements may be formal and written, or informal mental
expectations of meeting their purpose or satisfying their needs. If
a product meets formally defined "requirement specifications," yet
fails to be a quality product from the customers perspective, the
requirements are defective.
If an application is designed and built to meet the functional requirements
signed off by the business sponsors, and during final testing the
business sponsors reject the application as not meeting their needs,
what does that say? Either the requirements specification or the
analysis and design process is defective.
Quality also means meeting customers needs, not necessarily exceeding
them. The luxury automobile producer Rolls Royce went
bankrupt in the early 1980s. Analysis revealed that, among other things,
Rolls Royce was improving components that the luxury
automobile customers felt were irrelevant and polishing parts they
did not care about. This drove the price beyond what the
luxury-automobile customer felt was value for money. Quality means
improving the things customers care about and that make their lives
easier and more worthwhile. On the other hand, when Lexus sought to
make its first major redesign of its highly rated LS 400 luxury
automobile, representatives of the company sought out their existing
customers. They even visited the homes of a variety of LS 400
owners to observe home furnishings, what kind of leather they had on
their attaché cases, and other minute details to get a sense of
their
customers subconscious expectations.
What Is Data?
Before we can describe information or data quality , we must understand
what data is, what information is, and why information quality
is required. To define information quality, we must define data and
information. And because the ultimate objective of business is to
achieve profit or to accomplish its mission, we must define what we
mean by knowledge and wisdom. For it is in wisdom, or applied
knowledge, that information is exploited, and its value is realized.
Data
Data is the plural form of the Latin word datum, which means "something
given." It comes from the neuter past participle of the Latin
word dare, "to give." In the context of classical computer science
the term data has come to mean numeric or other information
represented in ways that computers can process. However, we define
data from a business perspective and independent of information
technology. The Oxford Dictionary defines fact as something "that is
known to have happened or to be true or to exist." Simply stated,
data is the representation of facts about things.
Data as Things or Entities
Data represents things or entities in the real world. Websters Dictionary
defines entity as "something that has separate and distinct
existence and objective or conceptual reality." My son, Chancellor,
is at the time of this writing a student at Middle Tennessee State
University (MTSU). Chancellor and MTSU are entities; that is, they
exist. When modeling data we represent the classification of entities
that have similar characteristics as an entity type. For example, Student
is an entity type that classifies the role that a Person such
as Chancellor plays in his relationship to MTSU. MTSU is also an entity.
MTSU is one occurrence of a classification of
Organizations in a role called an Academic Institution.
The statement, "Chancellor is a student at MTSU" is a statement of fact,
or, in other words, data. This can be represented graphically in
an entity relationship diagram as shown in Figure 2.1.
Figure 2.1 Entity relationship diagram example.
Data as Facts or Attributes
Data is a symbol or other representation of some fact about some thing.
My sons name is Chancellor. That is a fact. The type of fact,
first-name, is an attribute type. "Chancellor" is the actual value
of the attribute type first-name for my son and is not to be
confused with the value "Chancellor" of a different attribute type
Title of an entity type Employee of Academic
Institution.
Data is the raw material from which information is derived and is the
basis for intelligent actions and decisions. As an example,
"16155551212" represents a fact that is true. While it represents something
real in the world, this data without a descriptive definition
or a context is meaningless. Data is only the raw material from which
information may be produced.
Information
If data is the raw material, information is a finished product. Information
is data in context. Information is usable data. Information is the
meaning of data, so facts become understandable. The previous example
of data becomes understandable information when one knows
that +1 (615)555-1212 is the telephone number of information directory
service for Nashville, Tennessee, and surrounding areas.
It includes country code 1, area code 615, and telephone exchange 555
and number within exchange 1212.
Information quality requires quality of three components: clear definition
or meaning of data, correct value(s), and understandable
presentation (the format represented to a knowledge worker). Nonquality
of any of these three components can cause a business
process to fail or a wrong decision to be made. Information is applied
data and may be represented as a formula:
Information = f(Data + Definition + Presentation)
From a business perspective, information may be well defined, the values
may be accurate, and it may be presented meaningfully, but still
not be a valuable enterprise resource. Quality information, in and
of itself, is useless. But quality information understood by people can
lead to value.
Knowledge
Quality information becomes a powerful resource that can be assimilated
by people. Knowledge workers plus quality information provide
the potential for information to have value. A database without knowledge
workers using it produces as much value as a product
warehouse without ordering customers.
Knowledge is not just information known, it is information in context.
Knowledge means understanding the significance of the
information. Knowledge is applied information and may be represented
as a formula:
Knowledge = f(People + Information + Significance)
Knowledge is the value added to information by people who have the experience
and acumen to understand its real potential. With the
continuing evolution of information technology, organizations are now
able to capture knowledge electronically, organize its storage, and
make it sharable across the enterprise. The advances in Internet, intranet,
the World Wide Web, and data mining are expanding the
horizons of sharable data in both data warehouses and in operational
databases.
It is possible, however, to have a wealth of enterprise knowledge but
still see an enterprise fail. Knowledge has value only to the extent
that people are empowered to act based on that knowledge. n other words,
knowledge has value only when acted on.
Wisdom
The penultimate goal in any organization is to maximize the value of
its resources to accomplish its mission. The information resource is
maximized when it is managed in a way that it has quality and when
it is easily available to those who need it. People resources are
maximized when they are trained, provided resources, including information,
and empowered to act, carry out the work of the enterprise,
and satisfy the end customers. Wisdom is applied knowledge and may
be expressed in the formula:
Wisdom = f(People + Knowledge + Action)
The goal of information quality is to equip the knowledge workers with
a strategic resource to enable the intelligent learning organization.
Peter Senge defines the learning organization as one that "is continually
expanding its capacity to create its future" through learning and
shared learning.3
3 Peter Senge, The Fifth Discipline, New York: Doubleday, 1990, p. 14.
The intelligent learning organization is one that maximizes both its
experience and its information resources in the learning process. The
intelligent learning organization shares information openly across
the enterprise in a way that maximizes the entire organization (see Figure
2.2).
Figure 2.2 The intelligent learning organization.
In the Information Age, the dysfunctional learning organization is at
a distinct disadvantage. The term dysfunctional means "impaired or
abnormal functioning." Dysfunctional organizations try to operate with
inconsistently defined islands of proprietary data "owned" by
business-areas, whose quality serves to meet only "my" business areas
needs (see Figure 2.3). Dysfunctional organizations are hampered
by nonquality information that prevents them from sharing information
and knowledge. Nonquality information keeps these organizations
from being effective and competitive, because "knowledge of markets,
customers, technologies, and processes helps any organization
grow; . . . knowledge gains added power when it is the primary ingredient
of a business" to facilitate learning as a competitive weapon.4
4 Thomas A. Stewart, Intellectual Capital, New York: Doubleday, 1997, p. 179.
Figure 2.3 The dysfunctional learning organization.
Since the end result of data is to perform work successfully, the quality
of that data will either hamper or facilitate correct business
actions.
What Is Information Quality?
There are two significant definitions of information quality. One is
its inherent quality, and the other is its pragmatic quality. Inherent
information quality is the correctness or accuracy of data. Pragmatic
information quality is the value that accurate data has in supporting
the work of the enterprise. Data that does not help enable the enterprise
accomplish its mission has no quality, no matter how accurate it
is.
Inherent Information Quality
Inherent information quality is, simply stated, data accuracy. Inherent
information quality is the degree to which data accurately reflects
the real-world object that the data represents. All data is an abstraction
or a representation of something real. Jean Baudrillard, the
French semiologist,5 observes that the very definition of the real
becomes "that of which it is possible to give an equivalent
reproduction."6
5 Semiology is the science dealing with signs or sign language.
6 The Columbia Dictionary of Quotations is licensed from Columbia University Press. Copyright © 1993 by Columbia University Press.
Data is an equivalent reproduction of something real. If all facts that
an organization needs to know about an entity are accurate, that
data has inherent qualityit is an electronic reproduction of reality.
For example, if someone has a data value of "October 24, 1976" for
my daughter Ashleys "Birth Date," that data has inherent quality.
Inherent information quality means that data is correct.
Pragmatic Information Quality
Pragmatic information quality is the degree of usefulness and value
data has to support the enterprise processes that enable accomplishing
enterprise objectives. In essence, pragmatic information quality is
the degree of customer satisfaction derived by the knowledge workers
who use it to do their jobs.
Data in a database or data warehouse has no actual value; it only has
potential value. Data has realized value only when someone uses it
to do something useful; for example, to ship an order to a customer,
or to determine the correct location to drill a well shaft. Pragmatic
information quality is the degree to which data enables knowledge workers
to meet enterprise objectives efficiently and effectively.
Information quality lies in its ability to satisfy its customers, those
who use the data in their work. For example, if a college has recorded
a
data value of "27" for my son Chancellors senior high school year
"Composite ACT Score," that data has inherent quality; it is correct. If
that college uses "Composite ACT Score" values of 26 or higher as a
means of automatic acceptance, and sends letters to those
prospective students having a "Composite ACT Score" meeting that criteria,
that data has pragmatic information quality. Having a
correct data value and using it enabled Middle Tennessee State University
to meet an objective of increasing its entering student average
ACT scores for the Fall 1997 year.
It is possible to have inherent information quality without having pragmatic
information quality. Data not required to support any
business processes, nor required to make any decision, nor useful in
trend analysis is irrelevant. Even if the values are correct, and
therefore have inherent quality, that data is useless, and has no value
to the enterprise. In fact, it is actually nonquality information because
it costs the enterprise money and resources to acquire and maintain
but adds no value. It has a negative net worth. If my insurance
company knows that the interior upholstery of my automobile is black,
but that fact is not useful in any of its business processes, it lacks
quality. In fact, it increases the companys cost of doing business,
and is passed on to me in higher insurance premiums.
Pragmatic information quality prevents people from:
Performing work incorrectly or making a wrong decision
Performing work over again because it was previously performed incorrectly
Recovering from the impact of making a wrong decision
Taking unnecessary time to investigate the integrity of the data before using it
Performing calculations or reformatting the data before it can be used
Hunting for additional information in order to use the data
Losing customers because it caused work to be performed incorrectly
Causing unrecoverable damage
Missing business opportunities
Miscommunicating within the business or with end customers and other information stakeholders
Information Quality Defined
The same premise of quality of consumer products holds true for information
quality. To define information quality, one must identify
the "customers" of data, the "knowledge workers" who require data to
perform their jobs. Information quality is "consistently meeting
knowledge worker and end-customer expectations" through information
and information services7, enabling them to perform their jobs
efficiently and effectively. Information quality describes "the attributes
of the information that result in information customer satisfaction."8
7 Larry English, Information Quality Improvement: Principles, Methods,
and Management. Seminar 5th Ed (Brentwood, TN:
INFORMATION IMPACT International, Inc., 1996), p. 1.5.
8 Madhavan K. Nayar, "A Framework for Achieving Information Integrity," IS Audit & Control Journal, Vol. II, 1996, p. 30.
Information quality exists when information enables knowledge workers
to accomplish their "enterprise" objectives. Information quality is
measured not just by the immediate beneficiaries, but also by the downstream
knowledge workers. Quality information eliminates the
need for transforming interface programs, because specific facts are
defined and represented in the same way across the enterprise.
Let us now examine the elements of information quality:
"Consistently meeting knowledge worker and end-customer satisfaction"
"Consistently"
When knowledge workers get information about a given entity or event,
they expect consistent quality. They know ahead of time the level
of quality of the data with which they work. For some decision support
processes, knowledge workers can tolerate some degree of error
and omission if they are aware of the degree and nature of error. If
there are wide swings in the reliability of data in the data warehouse,
knowledge workers may resort to gut feel as their decision support
system, rather than trust what they perceive as unreliable data in an
untrustworthy electronic decision support system.
Consistently means the information quality meets all knowledge worker
needs, not just some. If one set of knowledge workers requires
95 percent accuracy and another 99 percent accuracy, then a 99 percent
accuracy is required to consistently meet expectations.
Consistently also means that if knowledge workers have to use data about
the same thing from two different databases, whether two
operational databases or an operational database and the data warehouse,
they expect the data to agree. If I get information about John
Smith from our central database, from the marketing database, from
the accounting database, and from the data warehouse, I expect
consistency of the attributes that are supposed to be the same in all
four data databases.
Failure to maintain consistency in redundant databases remains one of
the most prevalent information quality problems. If there is a
business case for building (and buying) redundant databases, there
is a business case for maintaining its consistency.
"Meeting"
Some data is required to be zero-defect data. Domain reference data
such as medical diagnosis codes and product prices must have 100
percent accuracy if medical claims and product sales are to be accurate.
Zero-defect data is required when the consequences of
nonquality cause major process failure or catastrophic consequences.
Consider the consequences of an inaccurate temperature value to
be set in a monitor of a steel blast furnace. The result may cause
the furnace to overheat, resulting in a breakout of molten steel from its
container.
However, not all data is required to be complete, or even to be precisely
accurate. Many decisions may be made from warehouse data
that is incomplete. Correct decisions may be made from data that contains
some degree of error, when this is factored into the decisions.
Some data, especially data about business events, may not be able to
be captured about the initial business event opportunity without
extensive investigation and event recreation. For example, variables
in a scientific experiment not captured during the point of contact with
the event, may not be able to be re-created at any expense. Even conditions
that led to a customer inquiry about a product or service
may be lost forever if not captured during that inquiry.
"Knowledge Worker and End Customer"
Who is able to discern quality information? Knowledge workers who require
the data to do their jobs. The term knowledge worker as
used in this book means the role in which one requires or uses data
in any form as part of their job function or in the course of performing
a process. Hence, a knowledge worker is a customer of information.
Knowledge workers, as information customers , determine
whether data is quality or not based upon how well that data supports
their ability to do their jobs.
Virtually all employees are knowledge workers. . Executives who make
decisions are obviously knowledge workers. Business analysts
who require accurate trend data are major customers of the data warehouse.
Warehouse clerks who fill orders and builders who use
architectural plans to build houses are knowledge workers. Even the
order entry clerk who creates orders is a knowledge worker of
product information.
Any function that calls itself a quality initiative must have the customer
as its sole focus. A quality function that does not focus on the
needs and requirements of its customers will ultimately fail.
Data warehouse architecture cannot be developed without understanding
the needs of the warehouse customers. Who are the customers
of the data warehouse? What questions do they need answered? What decisions
do they make, and what information is required? To
assume one simply needs to load data from the operational databases
into the data warehouse guarantees a nonquality information
product.
Immediate Information Customers
Immediate information customers are those knowledge workers who are
in the same department or business area as the producer of the
data. For example, order entry personnel are both producers and knowledge
workers of customer data. One clerk may create John
Smiths customer record when he first calls in an order. For subsequent
orders, the clerk receiving John Smiths call becomes a
knowledge worker, retrieving Johns customer record in order to create
a new order for him. Because the producers of the customer
data also use the information, there is a high stake in getting correct
data needed to take an order.
Downstream Information Customers
The departmental knowledge workers are not the only customers of data.
Not only does the order entry department need Customer
data, so does order fulfillment, customer service, accounts receivable,
marketing, and possibly product research and development. These
downstream knowledge workers also expect quality customer information
to perform their processes of filling orders, invoicing and
applying payments, marketing efficiently and effectively, and developing
new products. Data in one database about a given entity is
nonquality if it cannot be used by other knowledge workers who have
a stake in that data.
A systemic problem has been caused by the past practices of developing
applications from a myopic functional or departmental view of
data requirements. The fact of the matter is that data created in one
department by one application may have many more knowledge
workers outside the originating department who depend on that information.
Quality information is data that satisfies not only the immediate customers,
but also satisfies the downstream information customers
without major transformation. If common data required in many different
business areas, such as name and address, must be transformed
by interface programs into different formats for different applications
to use, an information quality problem exists. The cost of
transformation interfaces diminishes the value of the data by reducing
the profit derived from the use of that data. The interface programs
also introduce another point of potential error introduction into the
process.
"Satisfaction"
The bottom line is that conscientious employees want to do their jobs
well, and they expect to have the necessary resources available to
carry out their work in exchange for fair pay. Knowledge workers who
are required to use information to perform their work, that
employee expects, and deserves, to have the necessary information (resource)
with the right quality available to perform that work
efficiently and effectively.
The real goal of information quality is to increase customer and stakeholder
satisfaction. In fact, information quality can be seen in and
measured by end-customer satisfaction. Suppose a customer who orders
three widgets but receives only two because the order taker
entered "2" instead of "3." The customer, expecting three black widgets,
will be an unhappy customer because of nonquality information.
Information Quality Components
Earlier we indicated that information can be represented by the formula:
Information = f(Data + Definition + Presentation)
The three components that make up the finished product of information
are separate and distinct components that must each have quality
to have information quality. If we do not know the meaning (definition)
of a fact (data), any value will be meaningless and we have
nonquality. If we know the meaning (definition) of a fact, but the
value (data) is incorrect, we have nonquality. If we have a correct value
(data) for a known (definition) fact, but its presentation (whether
in a written report, on a computer screen, or in a computer-generated
report) lacks quality, the knowledge worker may misinterpret the data,
and again we have nonquality.
Data Definition and Information Architecture Quality
Data definition refers to the specification of data, that is, the definition,
domain value set, and business rules that govern data. Data
definition quality is the degree to which data definition: accurately
describes the meaning of the real-world entity type or fact type the data
represents, and meets the needs of all information customers to understand
the data they use. Information customers include both
business and information systems personnel:
Knowledge workers must know the meaning of information in order to perform their work.
Information producers must know the meaning of information along with
valid values and business rules in order to
create it or keep it updated.
Data administration staff must know the meaning of information along
with valid values and business rules in order
to develop accurate data models.
Database administration staff must know the meaning of information along
with valid values and business rules in
order to design high-integrity databases and code triggers correctly.
Systems analysts must the know meaning of information along with valid
values and business rules in order to design
high-integrity application models.
Application developers must know the meaning of information along with
valid values and business rules in order to
develop high-integrity application logic.
Information architecture quality is the degree to which the data structure:
Implements the inherent and real relationships of data to represent the real-world objects and events.
Is stable, enabling new applications to reuse the original data without
modification and only require new,
non-redundant entity types (and files) to be created, and new attributes
(and fields) to be added to existing data
models or databases. Database stability means new applications can use
data in existing databases without changes in
the structure of the data model or database, only adding new data.
Is flexible, supporting changes in how the enterprise performs its processes
without significant change to the data
model or database. Database flexibility means two lines of business can
merge to eliminate duplicate overhead and to
maximize cross-selling with minimal change to the database design. Database
flexibility means businesses can
reengineer processes with minimal change to the database design.
Clear, precise data definition is required to assure clear communication
among all handlers of information. Data definition is to data
(content) what Oxford or Websters Dictionary definition is to an English
language word. Without knowing the meaning of words, how
can people understand and use them correctly? Without knowing the precise
meaning of data, how can anyone understand and use it
correctly?
You cannot assume that others in the organization understand the meaning
of business terms and data without having a definition. People
in general must use a dictionary from time to time. Just as a language
requires lexicographers to identify and define the meaning of words,
so an enterprise requires business lexicographers to define the precise
meaning of business terms and facts. Business terms can mean
different things in different contexts, so each definition and context
must be maintained in an enterprise business glossary.
Data definition quality applies to concepts. Does the enterprise have
a clear understanding of the of customer, or order? Does it have a
clear understanding of customer first service date or order date? Without
it, information producers will not know the correct values,
and knowledge workers will not know the meaning of the data. And without
that, business communication will fail and business
performance will suffer.
Data definition quality is a characteristic and measure of data models
produced by the application and data development processes. The
measures of data definition quality are described in Chapter 5, "Assessing
Data Definition and Information Architecture Quality."
Data Content Quality
Information quality requires both data definition and data content quality.
Data content quality is the degree to which data values
accurately represent the characteristics of the real-world entity or
fact, and meet the needs of the information customers to perform their
jobs effectively
Data content quality applies to actual occurrences of things. Does the
enterprise have an accurate representation of Customer "John
Smith" in order to maintain an effective customer relationship with
John Smith? Does the enterprise have the accurate values for John
Smiths Order, number 12345, in order to fill it properly and identify
the trends of product sales and customer needs?
Data content quality is a characteristic and measure of data created
and updated by business processes and the applications that
implement them. The measures of data content quality are described
in Chapter 6, "Information Quality Assessment."
Data Presentation Quality
Business processes can still fail even when data is accurate, complete, and conforms to a clear precise definition. Processes can fail if:
Data is inaccessible
Data is not available on a timely basis
Data is presented in an ambiguous way or with a label inconsistent with
the data name or definition, causing
misinterpretation
Data is presented in a way that requires excessive work to interpret
it, thereby introducing potential errors in the
additional processes required to make the data usable
Data is combined with other data incorrectly, producing incorrect derived or calculated data
Data presentation quality applies to information-bearing documents and
media, such as a report or window presenting the results of a
query of data from a database. Does the order filler have an accurate
presentation of Customer "John Smiths Order, number
"12345", in a format that enables him or her to efficiently and correctly
fill the order?
Two microwave ovens flash a message to signal the conclusion of their
heating processes. One message flashes "End," and the other
message flashes "Ready." When I first saw each message I had different
responses. With the "Ready" message I said, "Great, my food is
done." When I saw the "End" message my first thought was, "End of what?"
The message "End" is a message presented from the view of
the oven itself: "This is the end of my process." The "Ready" message
is presented from the customers perspective: "The food is ready
for you." Data presentation must focus on the needs of the knowledge
workers and their purpose for knowing the information. Data
presentation quality means knowledge workers can quickly and easily
understand both the meaning and the significance of the information
and apply it correctly to their work.
Because information is used for many different purposes, it will have
different presentation formats. Quality of presentation means the
format presented is intuitive for the use to be made of the information.
Data presentation quality is a characteristic and measure of data access
by and presentation to business personnel for their use in
performing their work. The measures of data presentation quality are
described in Chapter 6 "Information Quality Assessment."
Conclusion
Information quality is not an esoteric notion; it directly affects the
effectiveness and efficiency of business processes. Information quality
also plays a major role in customer satisfaction.
Information quality is not a subjective characteristic that cannot be
measured. It is measurable in the most fundamental of business
measures: the bottom line of the business.
Inherent information quality is the measure of how accurately data represents
the real-world facts that the enterprise should know.
Pragmatic information quality is the measure of how well information
enables knowledge workers (the information customers) to
accomplish business objectives effectively and efficiently, and to
satisfy end customers.
To put it another way, information quality is:
Quality
Knowledge
Characteristic
Worker Benefit
The right data
The data I need
With the right completeness All the data I
need
In the right context
Whose meaning I know
With the right accuracy
I can trust and rely on it
In the right format
I can use it easily
At the right time
When I need it
At the right place
Where I need it
For the right purpose
I can accomplish our
objectives and delight our
customers
Posted by Dan Law on March 02, 1999 at 16:11:32:
We have heard much about knowledge (K)and creating
a knowledge sharing culture. To me, however, two very critical
issues remain:
1) The contents and quality of the K we share:
We must not share K for its own sake. If the
ultimate purpose is to use the shared K for some productive ends, then
the
contents and quality of K we want our employees
to share become very important. The higher the quality, the better and
more useful the K is to the organization.
I personally see two basic types of K for sharing.
One is internal K: K that already exists within the organization (and its
individual employees). This K comes with the
academic background, previous training and accumulating experience of the
employees. It is already there, hidden within
the organization waiting to be externalized. The key is to purposefully
and
systematically EXTRACT it from the employees
and the organization. This has to do with hiring the right and bright people,
giving them the best possible training, creating
a sharing culture, supplying them with the right technology, creating K
repositories, and using the best K taxonomy,
etc...
Then there is the external K. This is K that
does NOT yet exist within the organization but is available outside. Vast
amount
of top quality K of this kind abounds and
awaits discovery. But it will have to be filtered and captured. Aside from
encouraging employees to externalize their
tacit K, what are we doing to equip and help them go outside to capture
targeted
K for use? Is our approach to capturing external
K systematic, and does it have the company's business objectives in mind?
2) The processes we use to turn shared K into innovations
This remains the most urgent and critical need
facing the entire KM movement. Even if the employees are sharing quality
and targeted K, if it is not put to productive
use, it will just sit there looking pretty. What are we doing to turn K
into
innovation?
In the coming knowledge century, the need to
share and manage K will no longer be an issue for debate. It remains for
the
progressive companies to figure out HOW they
can capitalize on the K they have (and/or capture the K they do not yet
have), and turn it into a competitive advantage
to fuel continuous innovation. This will be a life and death issue for
many
organizations, whose survivals are dependant
on the application of new knowledge.
So, allow me to post my question again: What can we do to turn K into innovation?